It might be a coincidence that I’ve been getting pinged about Kafka by recruiters a lot lately, or it might be that companies are starting to think about its applications more broadly in the context of whatever shape the “Agent Economy” takes. Either way, I couldn’t help but notice that the universe seems to be prodding me in that direction, and it got me thinking deeply about what the atomic units of systems design look like in that world. I’ve already been talking about what happens when the agentic paradigm strips away the need for SaaS entirely with colleagues and friends, and how companies are supposed to stay relevant in that world. But my passion has always been “Big Data” in whatever form that practice has taken throughout the decades of my career, so my pondering turned naturally to what this sea change looks like in the world of Data Engineering.
Transforming data is a problem that’s dissolving
Much of what Data Engineering does is fix the problem that application siloing introduced. When Salesforce needs to agree with Netlify and half a dozen other spreadsheets and vendor applications that are floating around an organization, so that someone on the revenue team can answer a specific question, that is where Data Engineers earn their paychecks. The entire Fivetran-into-Snowflake-into-dbt pipeline that we’ve collectively spent billions on exists to reunify the silos of data that SaaS applications create, so that humans can reconcile things for business purposes.
That’s not to say that these tools are bad… they’re not. They’re great at what they do. Moving data out of silos into one place is still necessary. What remains on top is the transformation layer: the dbt models, the Airflow DAGs, the SQL that cleans and joins and materializes. That’s the part agents can do.
Agents can be embedded in the stack to perform much of what data engineers do: they can reason about their business domain and directives and construct a plan for delivery based on what’s available. Agents do this with tools already. They conclude they need information from X Y and Z sources, pull the data, and build the prompt context dynamically. In much the same way, data engineering agents can deduce they need data from topic X, API Y, and database Z, build software to pull and normalize everything, aggregate/join, and ultimately, provide actionable insights and business value to downstream processes. So what I naturally start to wonder is whether there is an architecture that streamlines this approach to data engineering in much the same way that attempts are being made to streamline it for SaaS.
But what happens to data engineering infrastructure when AI agents start encroaching on the SaaS application layer? It’ll start to happen soon, in one form or another. Bain’s 2025 Technology Report lays out concrete scenarios where agentic AI disrupts the SaaS revenue model. Deloitte’s 2026 TMT predictions explore how agents begin absorbing the workflow automation that SaaS products traditionally provide. The question these analysts are asking is whether agents kill SaaS. The question I’m more interested in is what happens to the data infrastructure underneath it when they do.
The way I see it, a few things will happen. First, the event log survives because the moment you let autonomous systems make consequential decisions across organizational boundaries, you need infrastructure to prove what happened.
Second, the transformation layer is the layer that atrophies, because agents can build transformations for us. Data still needs to move from source systems to the event substrate; that’s engineering work that persists. What atrophies is the scheduled-batch-transform-and-land pattern; the dbt/Airflow DAG that runs nightly to clean, join, and materialize data so humans or downstream systems can query it. In the agent cell architecture, described later, transformations still happen. They just move from human-authored SQL models to agent-authored streaming consumers.
Third, the data warehouse survives as an important tool in the ecosystem for data standardization and organization, but its role as a primary store starts to diminish because it’s faster for agents to work directly with the streaming paradigm. Agents are interactive and need to respond with updated information instantly, which won’t happen if they have to run an expensive warehouse operation before they can act. Batch jobs are still necessary for building models and gold-tier datasets along with ad-hoc analysis (increasingly also done by agents) but when given a choice between running a nightly job to compute “churn risk by demographic” versus seeing those numbers right away, most businesses tend to prefer the latter.
What emerges are “pipeline agents” that replace the old nightly job runs with real-time answers to the same questions. Some data is inherently batch because it crosses organizational boundaries on someone else’s schedule. Pipeline agents’ machinery still works here, it just consumes whatever lands. Batch persists at the ingestion edge, where external data enters the substrate. Once it’s in the log, everything downstream is streaming.
The tradeoff with streaming architectures has always been complexity and overhead, but today’s models are rapidly closing the gap when it comes to managing those risks. Data at rest still flows to S3, seeking its natural low energy state, and the warehouse still reads and transforms it. But suddenly the calculus around “what can wait” changes fundamentally if agent pipelines are the norm; it’s now a lower bar because agents are scalable in a way that engineering departments aren’t.
Lastly, the separation between operational and analytical domains collapses. In the new agent-native architecture, they share the same event substrate (and a lot of companies already do this, it will just become the default). The orders machinery writes orders.placed to a Kafka topic. The fraud agent, the analytics agent, and the reporting agent all wire themselves up to consume from the same topic through independent consumer groups. What remains is computation; agent machinery consuming shared topics and materializing the views they need.
None of the components I’m describing are new. Kafka, materialized views, and streaming consumers all exist today. What’s new is who (or what) authors and operates these components, what the lifecycle looks like for each piece, and what the role of the data warehouse becomes.
Here’s what the shift looks like:

The log is demanded by the operational reality
When autonomous agents start making consequential decisions about how things are implemented, or how certain actions are taken, you need an immutable, ordered, replayable record of every decision and state mutation. The reason you need the log is governance. The alternative to a durable audit trail is trusting an autonomous system with no way to replay what it did or why. In any regulated industry, and increasingly in any enterprise context, that’s unacceptable.
We all know that agents make stuff up sometimes, so we are going to need durable logs that record these decisions, in addition to the raw data passing between the components of an org. The event log is the only data structure that gives you the ability to completely replay a sequence of events that led up to a decision. This will continue to be vital for compliance and auditing purposes, because even if agents eventually develop long-term memory, an agent’s self-reported history is not an independent audit trail. The log exists because you need a record the agent can’t edit (and this should be disabled at the platform level).
Most agentic systems today record agent actions to Postgres, which works fine for a single application with a handful of agents. It’s possible to scale this pattern to hundreds or thousands of collaborative agents all focusing on different business problems, but the question is whether that’s wise when most data engineering teams already use a distributed log system for event-driven pipelines. Kafka handles this kind of write volume without breaking a sweat. And if you’re already using it for streaming then you don’t actually need anything else.
To elaborate a bit, Kafka fits naturally here because it handles three layers of the architecture simultaneously. Layer 1 is the first-order domain events that flow between different parts of the system. Layer 2 is the orchestration layer where the agent records user questions, decisions, actions, observations, thoughts, improvements, architecture refinements, and so on. And layer 3 is where the derived events that agents synthesize themselves go. All of these layers are append-only, durable event logs at their core. You might be thinking “so is Delta lake or a Parquet partition” and you’re right. At the end of the day it all flows back to S3. But Kafka fits best here because it’s the only infrastructure that serves as both a real-time transport layer and a durable, ordered, replayable event store. Delta Lake gives you the store without the transport. A message queue gives you the transport without the durability. Kafka gives you both.
The event topology self-organizes
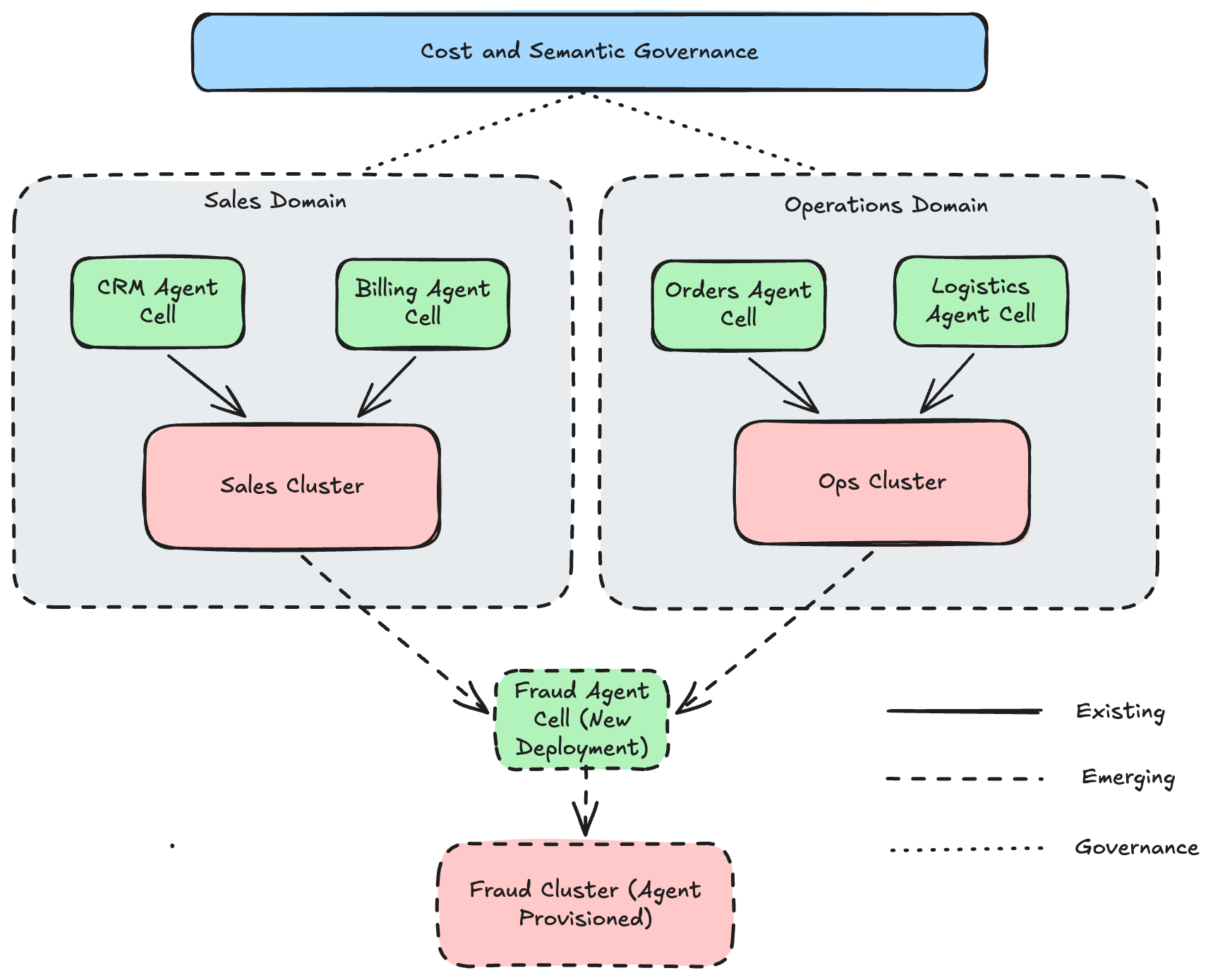
Ever seen those slime molds, particularly Physarum polycephalum, that can organize themselves into the most optimal network topology over time without relying on any form of centralized control? I think that’s what we get when we tell this system to regulate itself and find the most efficient substrate configuration for information transfer, assuming some mechanism for pruning stale topics and brokers exists (as it must). In this world, standing up a Kafka cluster is simply propagating the “food” (data) to the rest of the “organism” (other agents). This happens organically as agents decide they need access to certain kinds of information in order to derive value from various different projections over the available data supply. Obviously, there needs to be a governance layer to prevent garbage from accumulating and topic overlap, but over time the system converges on good coverage of the domain by providing the most valuable combinations of raw materials.
The first version of this idea is unglamorous. A fraud detection agent that needs to cross-reference sales events with operational events creates a new topic, subscribes to the relevant source topics, and starts emitting derived events into its own namespace. Agents creating their own clusters and topics over admin APIs is already technically feasible today. With adequate guardrails and governance, it can proceed on its own from there. No Jira ticket. No platform team review.
It’s important to emphasize that the agent’s responsibility shouldn’t be to process first-order domain events itself. Doing so would be way too slow and cost prohibitive. Instead, agents will create their own consumers that can aggregate, join, and compute over the raw data in whatever way is needed for their use cases. This extends to how agents build their own knowledge as well. A vector store for semantic retrieval, a structured table for key-value lookups, a text search index for discovery… These are all just materialized views over the same processed log data, optimized for different query patterns. The agent curates these projections for itself based on what it needs to provide business value. If one becomes stale or irrelevant, the agent retires it and builds a new one. If the agent needs to be rebuilt from scratch, the log is the source it reconstructs from. This is the event sourcing pattern applied to agent cognition.
What you might be noticing now is that the agent needs infrastructure to support its business function. Much like a cell nucleus needs organelles to survive. In this metaphor, the producer and consumer spawns are the appendages the agent “nucleus” uses to communicate with the outside world. The log is its long-term memory, the derived stores are its working set. All together they form an “agent cell”, a term I’ve coined to describe a deployable grouping of an agent along with its collection of memory, storage, and producer/consumer adapters. I’ve started building a proof of concept to explore what this looks like in practice.
One thing I want to acknowledge honestly: running an agent cell/event-log infrastructure at the scale implied by this architecture is expensive. This is not the kind of architecture I’d propose at a three-person startup with a handful of dbt models. Finding the point at which the ROI outweighs the cost of running a bunch of Kafka clusters is a genuinely interesting problem, one that makes the numerical analysis/systems design nerd in me overly excited. The answer today is certainly that this only makes economic sense at larger scales. But that boundary moves as compute gets cheaper, and it moves faster if agent cells can optimize their own infrastructure costs by pruning unused topics, retiring idle clusters, and right-sizing replication. The system that organizes its own topology can also optimize its own bill.
The semantic governance layer is the top of the stack
It’s hard enough to get humans to agree on ubiquitous language sometimes, one can only imagine how much worse this problem is when you introduce a bunch of autonomous, mostly unsupervised agent cells into the mix. What does “active user” mean? How do we define “revenue”? What shape is a “customer” when your CRM, billing, and operational systems all see it differently?
Consider what happens when an agent nucleus (LLM decision-maker) thinks “I want to count monthly active users” and it incorrectly conflates two conflicting definitions of that concept from two different subsystems when doing the join. One system encodes “a monthly active user is someone who has logged in in the last month”. The revenue system encodes “a monthly active user is someone who has paid us money in the last month”. The agent cell responsible for reporting needs to navigate this nuance and use agreed-upon definitions specified at the organization level. Otherwise the risk is that these systems produce numbers that are subtly wrong, or don’t match up with human expectations.
Academic research supports this. Agent-OM, published at VLDB, applied LLM agents to ontology matching, the task of determining whether two schemas describe the same concept. The results were promising but not yet reliable without human oversight. Recent work on LLM-supported collaborative ontology design, published in Frontiers, confirms that the problem is tractable but far from solved.
And so the semantic layer responsible for disambiguating concepts and aligning agent understanding with human guidance is essential and sits at the top of the stack. It is the highest-value component in the agent cell architecture, and the hardest to automate away. In fact it might never be, because it requires encoding human judgement about what concepts mean.
What’s truly interesting to me is that this happens to be the layer that provides a natural place to govern the operating costs for our self-organizing agent cell mesh. Agent nuclei have no intuition about whether the streaming join they just provisioned creates a shuffle nightmare, or whether other cells need the exact same repartitioning in order to solve a different problem. Each cell is locally correct, but naively duplicates work that could be pushed upstream to reduce the cost dramatically.
The problem compounds with domain complexity. Cell A repartitions the sales stream by order_id. Cell B repartitions the same sales stream by product_category. Cell C repartitions it by billing_region. A month later, Cell D needs the sales stream by order_id for a different use case. Without the governance layer, it creates its own repartition which is identical to Cell A’s. Now you’re paying for the same repartitioning twice. Multiply that across dozens of cells over a year and the waste is significant.
That’s the cost governance problem. Each cell is locally rational, it built the topology it needed. But globally the system is doing redundant work that no single cell can see. The governance layer solves this by knowing what all the business concepts mean, what the data relationships are, how the data physically moves, and how much it costs. It consolidates the above scenario to a single read with a fan-out, and maintains a registry so the next cell that needs “sales by order_id” or something higher level like “churn risk by region” reuses what already exists instead of building duplicate topics or transforms. As part of this process, someone or something needs to quantify the relative cost for different architecture permutations so that good decisions can be made. The more autonomous the infrastructure provisioning becomes, the more critical automated cost governance becomes.
Note that some transformations are universal and should be done once as a shared derived topic: account-level rollup, currency normalization, deduplication (similar to medallion bronze/silver/gold). The governance layer identifies these and promotes them to shared infrastructure. Use-case-specific transformations stay with the agent cell that needs them.
There’s a huge amount of depth here that I want to explore in further posts. For now, I will point out that the optimization the shared governance layer can’t do is eliminate the fundamental work of repartitioning. Three different partition keys means three different physical arrangements of the data. But what it can do is ensure that each unique repartitioning happens exactly once, the source is read minimally, and high-demand repartitions are maintained proactively rather than created on demand.
What we don’t know
It’s always fun to put on the speculation hat and dream about what comes next, and this post does a lot of that, so I want to be transparent about what we know today and what I’m guessing about.
The governance requirement for durable event logs is real and driven by the operational reality of autonomous systems. If you’re deploying agents that make consequential decisions, you need the log. That’s not speculative.
The self-organizing agentic mesh / agent cell architecture is 100% speculative. I’ve described a spectrum of “agents subscribe to and create topics dynamically” to “agents deploy their own infrastructure and curate their own knowledge bases”. The former is feasible today, the latter is further out. Effort should be focused on the former. That being said, grouping an agent with its supporting infrastructure as a deployable agent cell just makes logical sense. It’s simply another level of lego blocks.
The semantic governance layer is probably years away according to current research. “LLM agents can match ontologies with human oversight” is a long way from “agents autonomously agree on what revenue means across a network of 200 services.” This is the hardest unsolved piece and the biggest risk to the entire thesis.
And cost governance is wide open. I’ve described the problem and the shape of what a solution needs: a system that understands both what data means and what it costs to move. That system doesn’t exist yet.
I plan to write more about the practical mechanics of agent-orchestrated consumers, the economics of self-organizing event infrastructure, and the convergence of semantic and cost governance. In the meantime, the agent-cell-poc repo is where I’m experimenting with these ideas in code. There’s a lot to unpack. But the foundation looks like this: the event log as the source of truth, agents as the compute and orchestration layer, the warehouse as the largest derived view, and semantic contracts as the governance layer that holds it all together. All the pieces are familiar, but the next evolution of the organism they assemble is not.
Neil Turner is a Staff Data Engineer. He’s spent 15 years building event-driven data platforms at Microsoft, Amazon, StockX, and May Mobility.